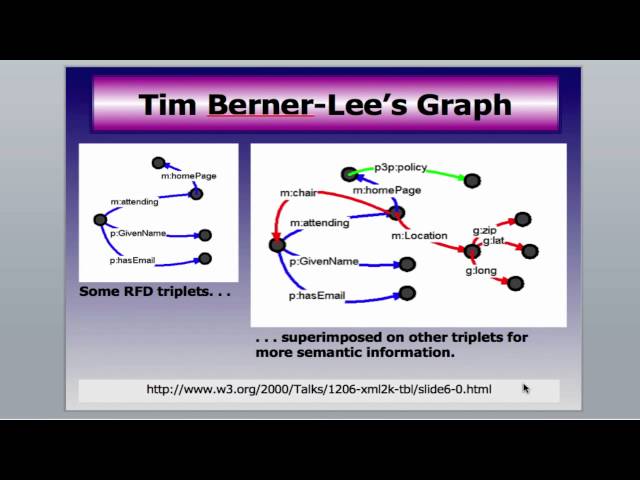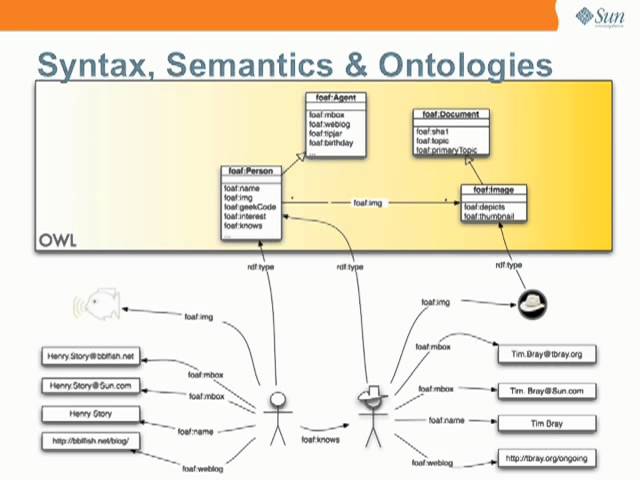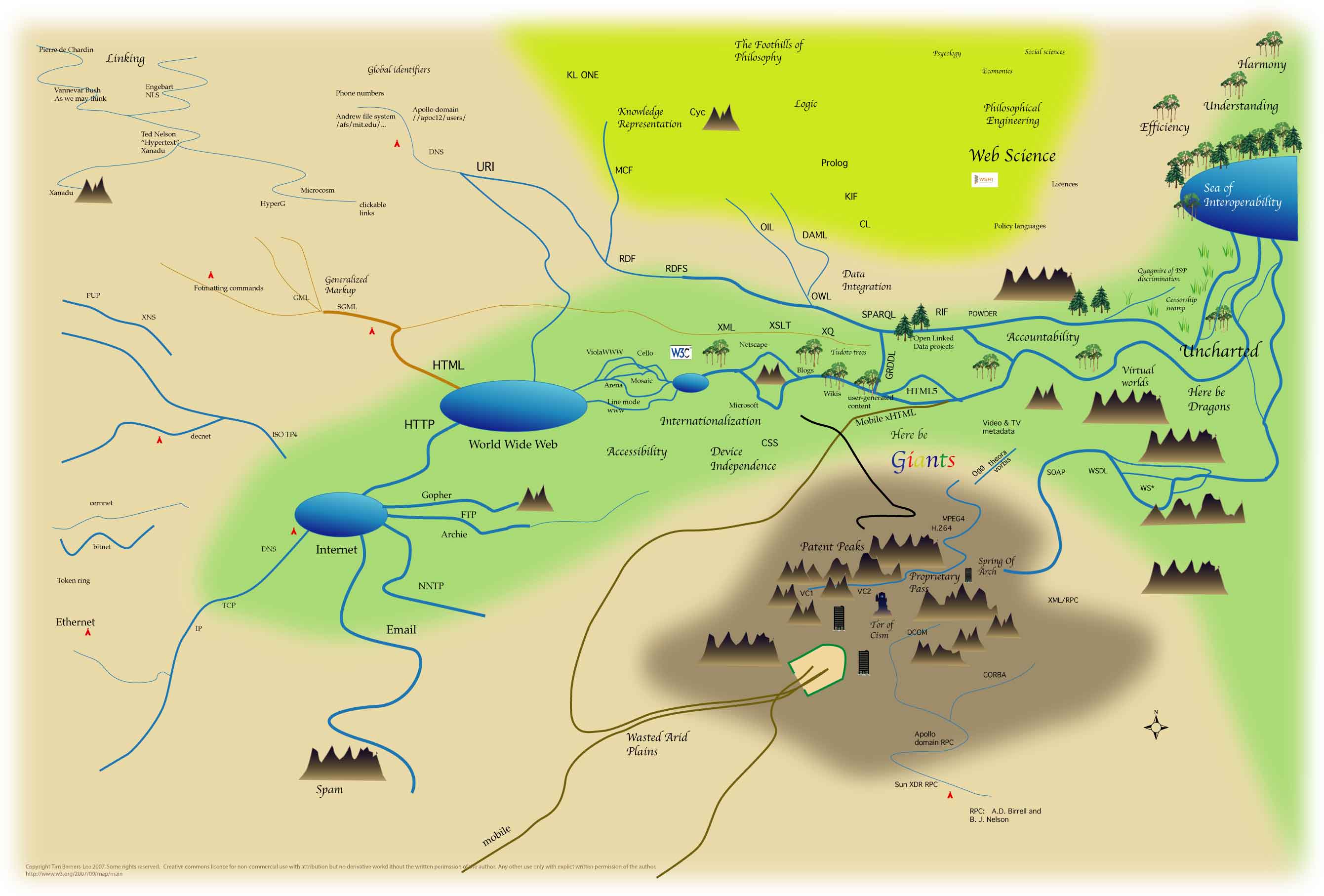
W3C was established by Sir Tim Berners-Lee using a set of particular ideological decisions that he made to produce the web we know. He has communicated these decisions, including his future vision of the Web from a standards development, or rather “network theory” perspective at Annenberg Networks Network seminar.
On the 6th of September last year, Jeff Jaffe replied to a query I had in relation to philosophical concepts pertaining to the growth of W3C and how it is legally structured, with the following;
“W3C is not a legal entity. W3C staff exists at four research universities (MIT, ERCIM, Keio, and Beihang) and legally it is a series of contracts that binds the universities and member organisation to work together on web standards.” Through this mechanism, the w3c patent policy is administered in relation to the role W3C plays, in internet governance.
W3C supports the growth of open-standards through a methodology that elects a particular field of endeavour, resourcing that field to support cooperative / collaborative group works, where technical solutions are designed in the form of ‘web standards’, and eventually overtime, these standards become released in a form supported by the meaningful use of the patent policy ecosystem structure. In more modern times, many of the projects taken-up by W3C start-off in a Community Group. Overtime the work produced in a Community Group or CG, may develop into a scope of work that’s developed further through an interest group, and finally a working group which in-turn results in the publication of standards implemented and provided ‘patent pool support’ by participating W3C Members. W3C works are generally carried out online, with mailing lists, code and even strategy works available online. Increasingly W3 also maintains online resources for Permanent Identifiers for the Web.
The role and meaningful utility of W3C has no known equal, within the sphere if its operationally realised purpose as has been developed since first established. Through the leadership (and somewhat onerous role) of Tim Berners-Lee; an array of semi-structured frameworks, backed by the international patent pools that power the web making possible the means to ensure free use of the global standards made by it (interoperable / cooperatively with others) are extensible in ways that have no similar alternative in the field of ICT ‘knowledge engineering’ ‘information management’ systems tooling. Whilst W3 works produce an array of constituent elements, it is principle custodianship of URI based layered technologies, built upon the underlying topological constituents of internet.
In works that moreover, seek to extend the beneficial development of the world via ICT, a remarkable influence is instrumentally built through the use and adaption of the ‘semantic web’ concept.

Internet, has reached a level where access to it is debated as a human right, yet the complexities of these arguments extend to the meaningful use of it, beyond simply access to it. The means through which this can now be better addressed makes instrumental use of works produced by W3C.
The link between internet and economics is now, inextricably linked; and it is worth noting, Internet Society as another key tenant in international internet governance worldwide; and whilst i note, that it is, arguably impossible, to produce anything without some form of inherent, ideological definitions woven into a specification (whether that be done via conscious, subconscious or as a result of unintended decision making processes) W3C and its fellow internet governance constituents are instrumental in the provision of intellectual property rights that entitle others to use ICT technologies without being required to pay financial royalties to companies for use of the meaningful human rights that relate and depend upon, the ability for persons communicate, as is a foundational required by all.
For more information see the W3 Website and related WikiPedia Article.

































![[#OHM13] the secure social web - bblfish](https://i.ytimg.com/vi/qnhdv8_xLTM/sddefault.jpg)